CREATE
Chain REAction Tool Environment
Reinforcement learning benchmark for solving complex tasks with tools

Diverse Tools
Challenging decision-making with a wide variety of tools
Physical Reasoning
Tool selection and postioning requires understanding of Physics
Multi-step Tasks
Suitable for Reinforcement Learning and Meta Learning

Customizable
Easily create new tasks with a simple interface
Environment Demo
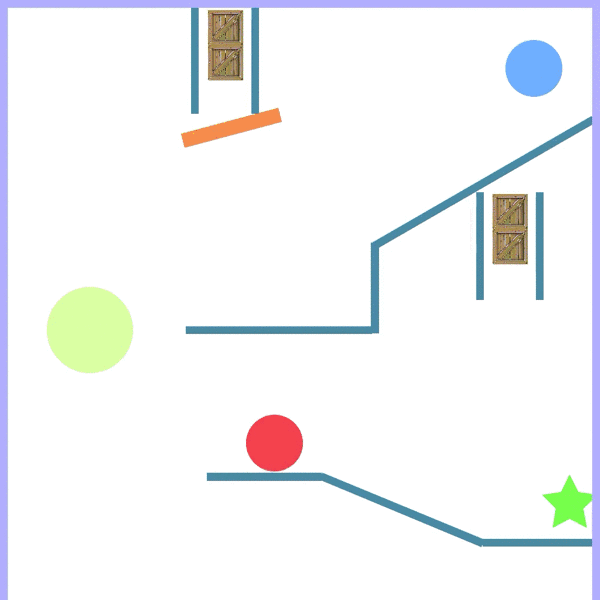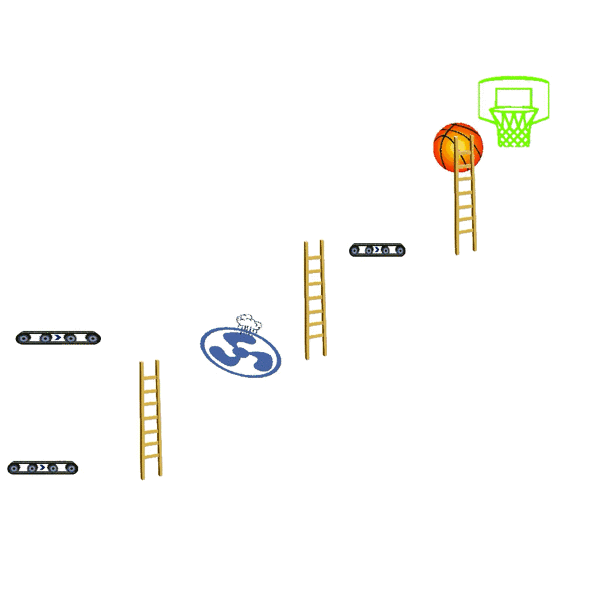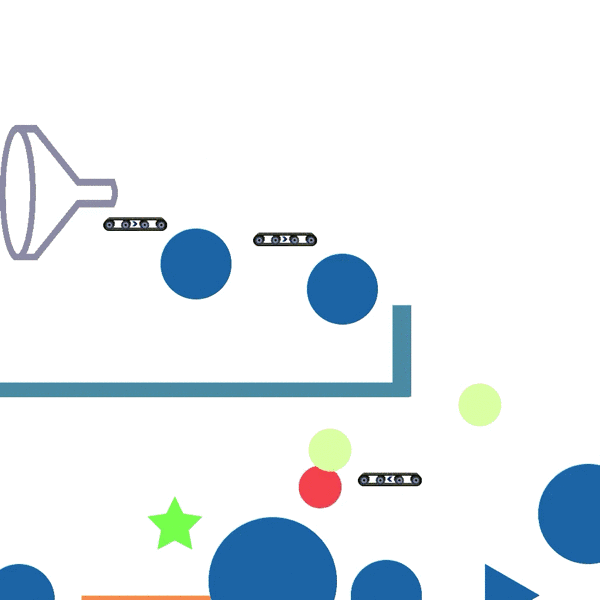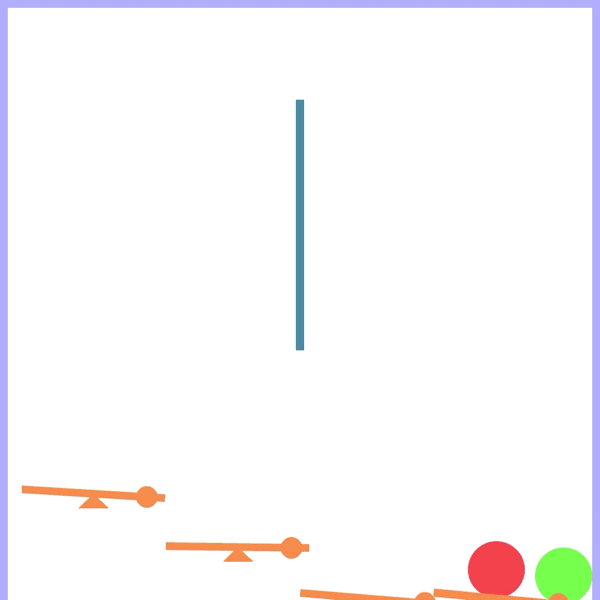
CREATE is based on the popular Physics puzzle The Incredible Machine. The objective is to sequentially select and position tools from an available set, to make the red ball (target) reach the goal (green) in various environments. 1-step demo is shown below, whereas the actual environment requires tools to be placed sequentially over time, as seen in a trained policy acting in tasks.
Drag and drop tools onto the screen and Play , Retry or Refresh
Demo is available only for desktop browser.
Tasks

Error!
Tools
Objective: Make ⬤ reach ★ or ⬤ | No overlap between tools | Task is solvable with given orientation of tools | Remove tool: drag it out of game window
Tools
The tool types available for the agent are illustrated below. The parameters of each tool such as size, angle, bounce or force are all configurable. Different tools have different properties that can be configured.

Ramp:
A basic angled platform with low bounce. |

Trampoline:
Bouncy platforms. |
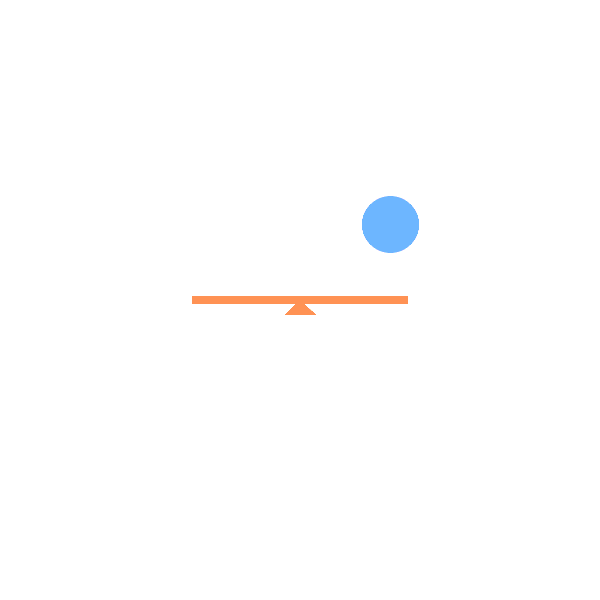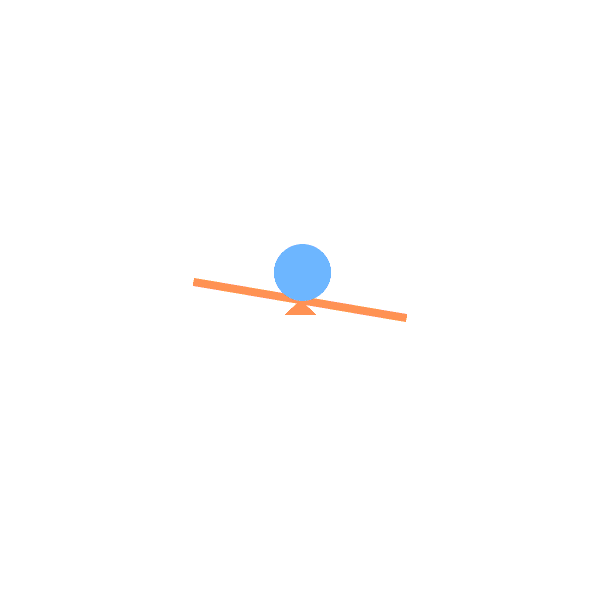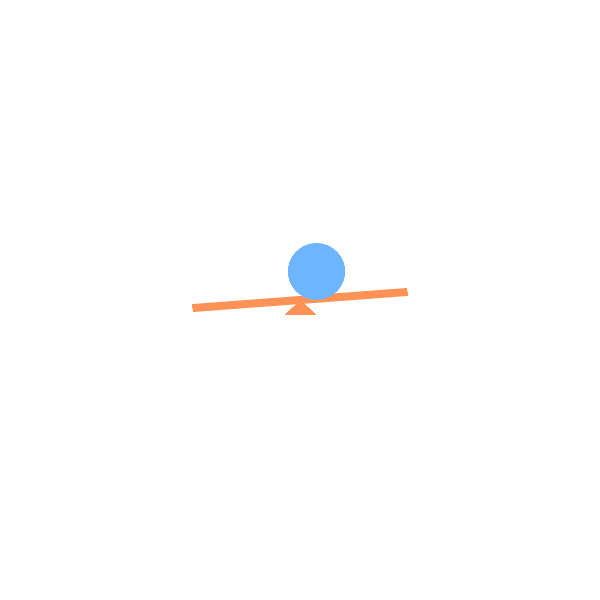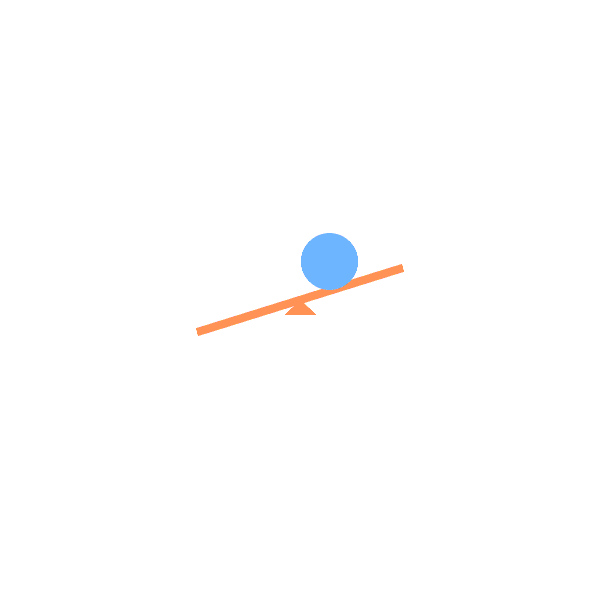
Lever:
Lever anchored to a hinge, which can rotate freely. |

See Saw:
See saws (with or without weight) with angle-limited rotation. |

Cannon:
Launches the ball in the direction of the cannon, adding speed. |

Fan:
Gently pushes the ball in the direction of the fan. Less powerful than the cannon. |
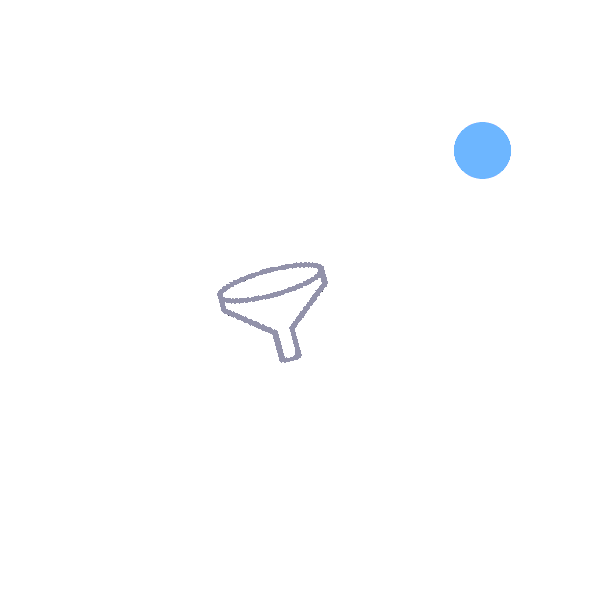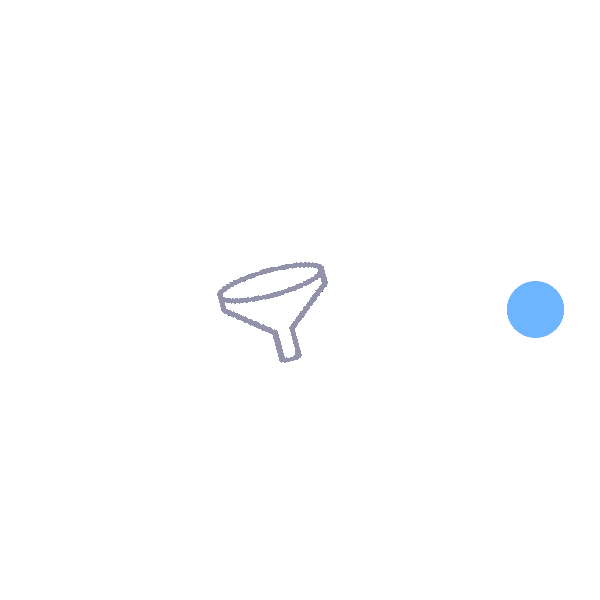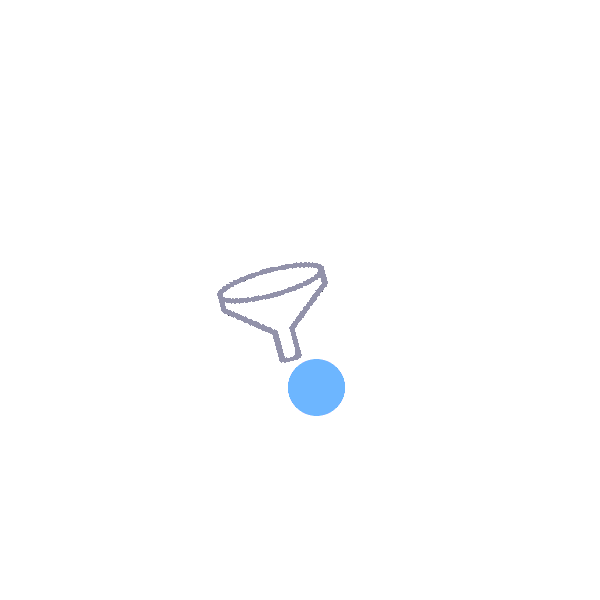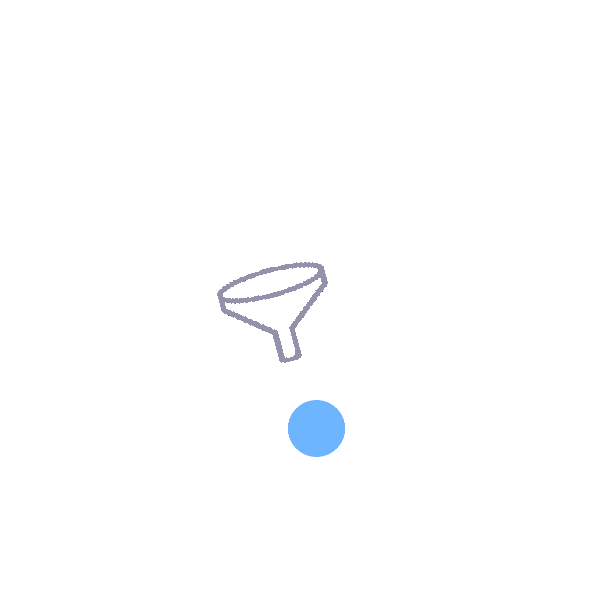
Funnel:
Transports an object from the wide end of the funnel to the narrow end. |

Bucket:
Catches an object from the open face and reflects off of other sides. |

Polygon:
Polygon-shaped tools: triangle, square, pentagon, hexagon. |

Bouncy Polygon:
Bouncy versions of triangle, square, pentagon, hexagon. |

Belt:
Conveyer belt to transport left or right at constant speed. |

Ball:
Low-bounce and high-bounce variations of round tools. |
Tasks
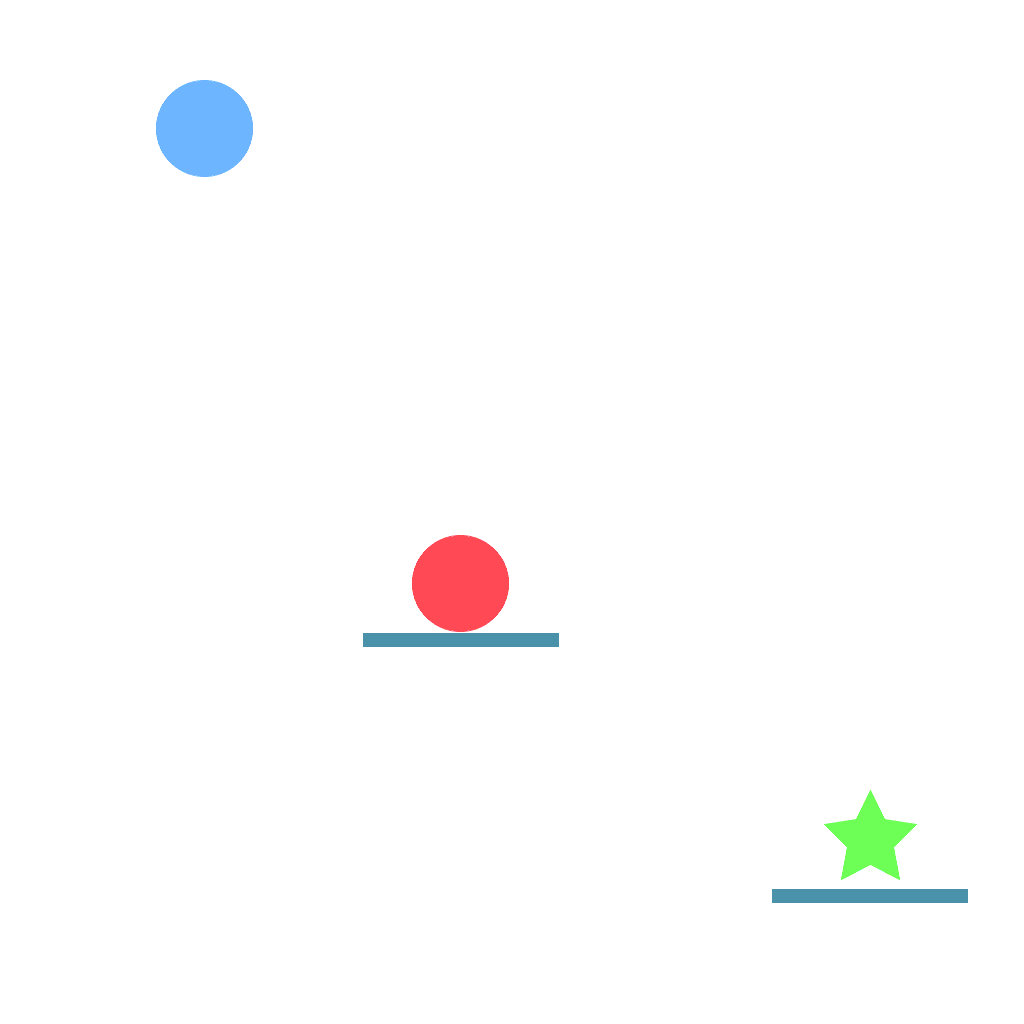
Push Task
Simply push the ball towards the goal.
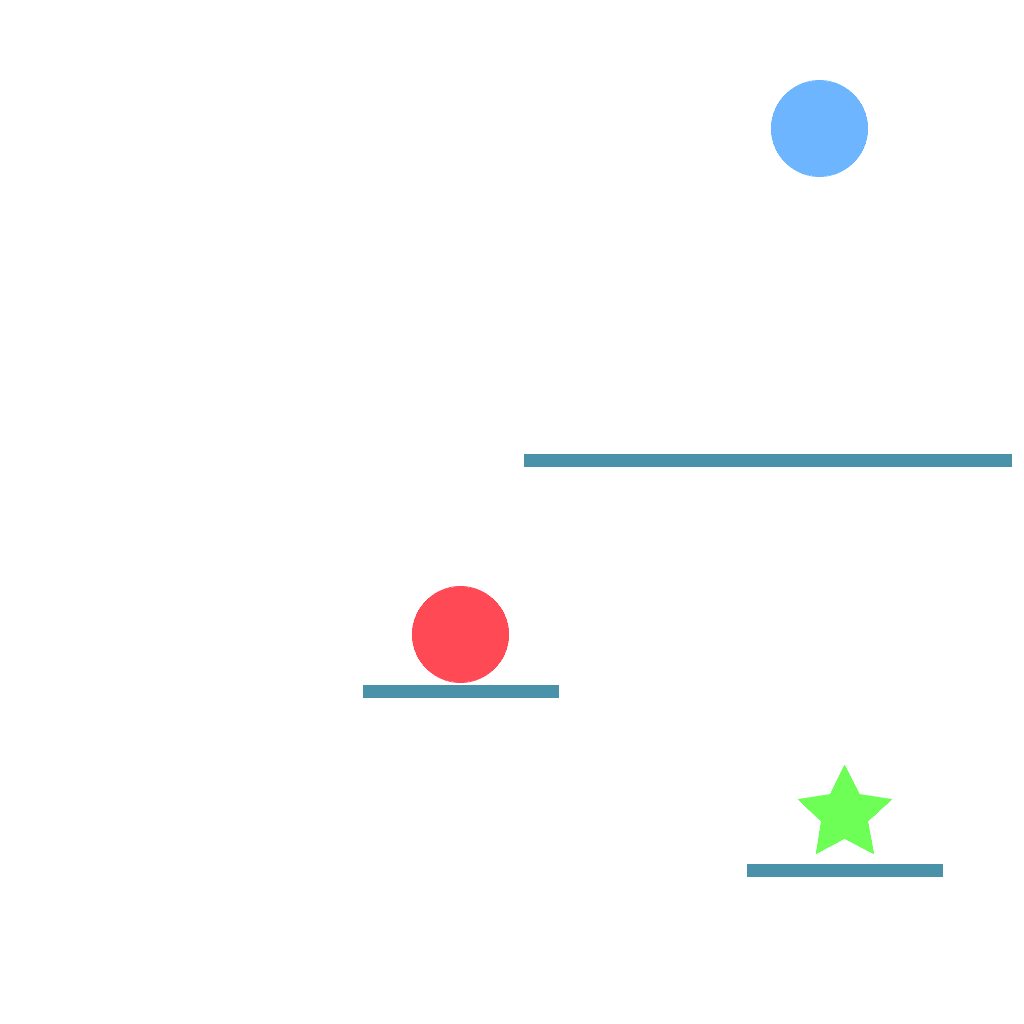
Navigate Task
Navigate around the turns to reach the goal.
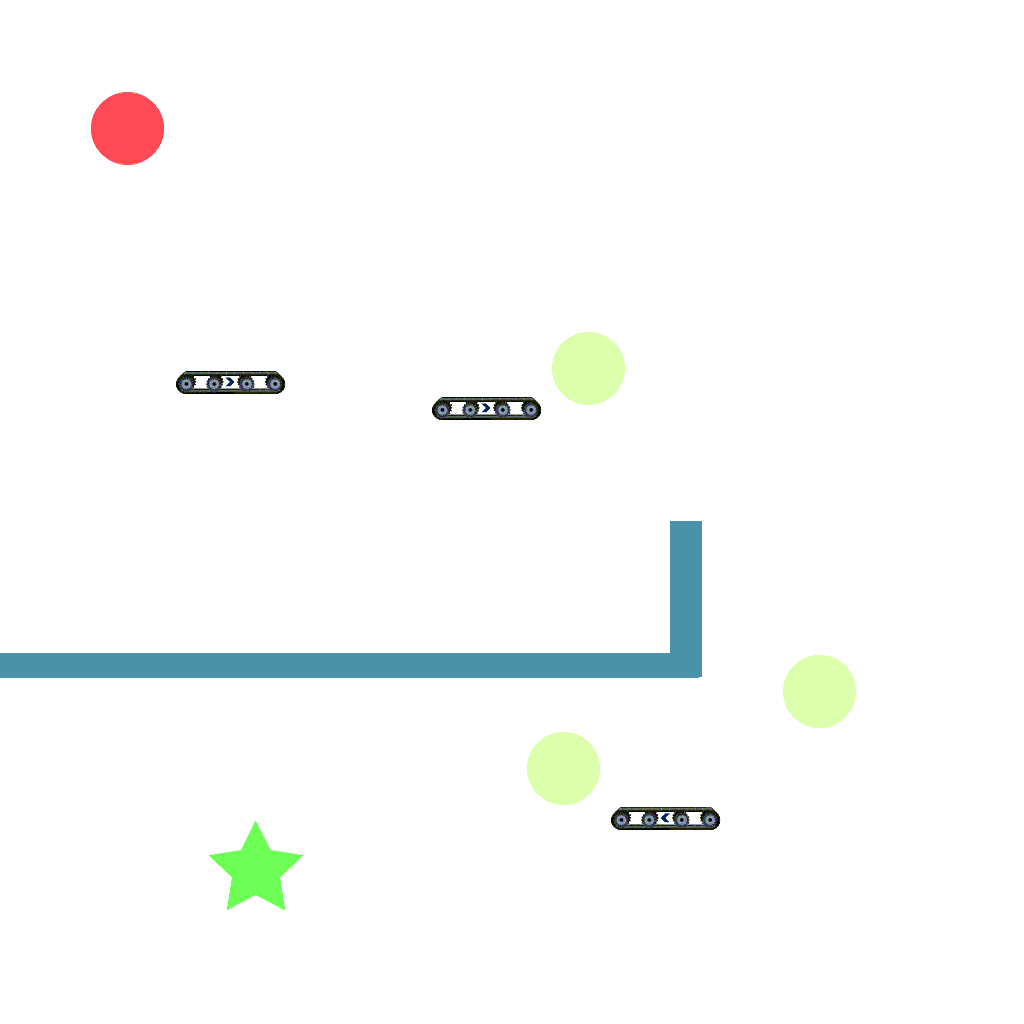
Belt Task
Long horizon task with lots of belts, twists and turns.
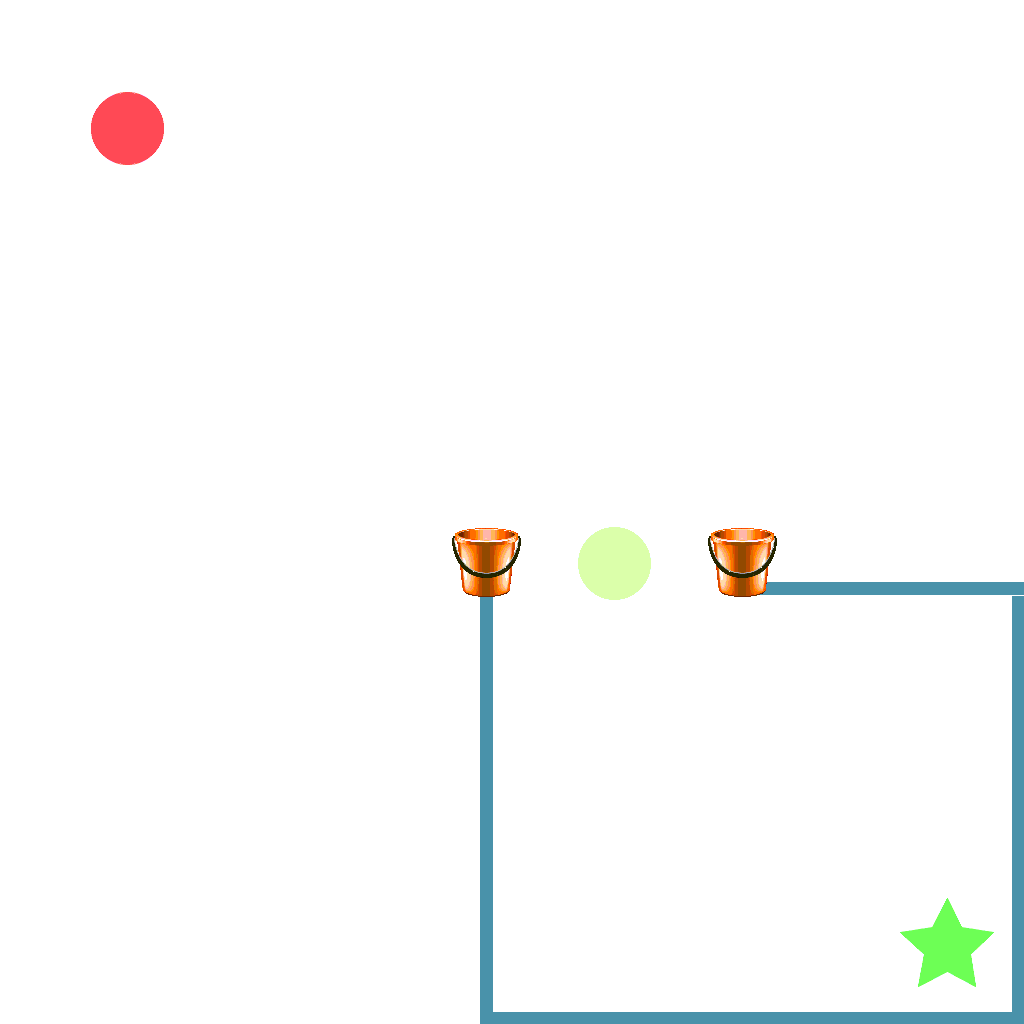
Buckets Task
Make sure the ball doesn't land on the buckets around the entrance to the goal.
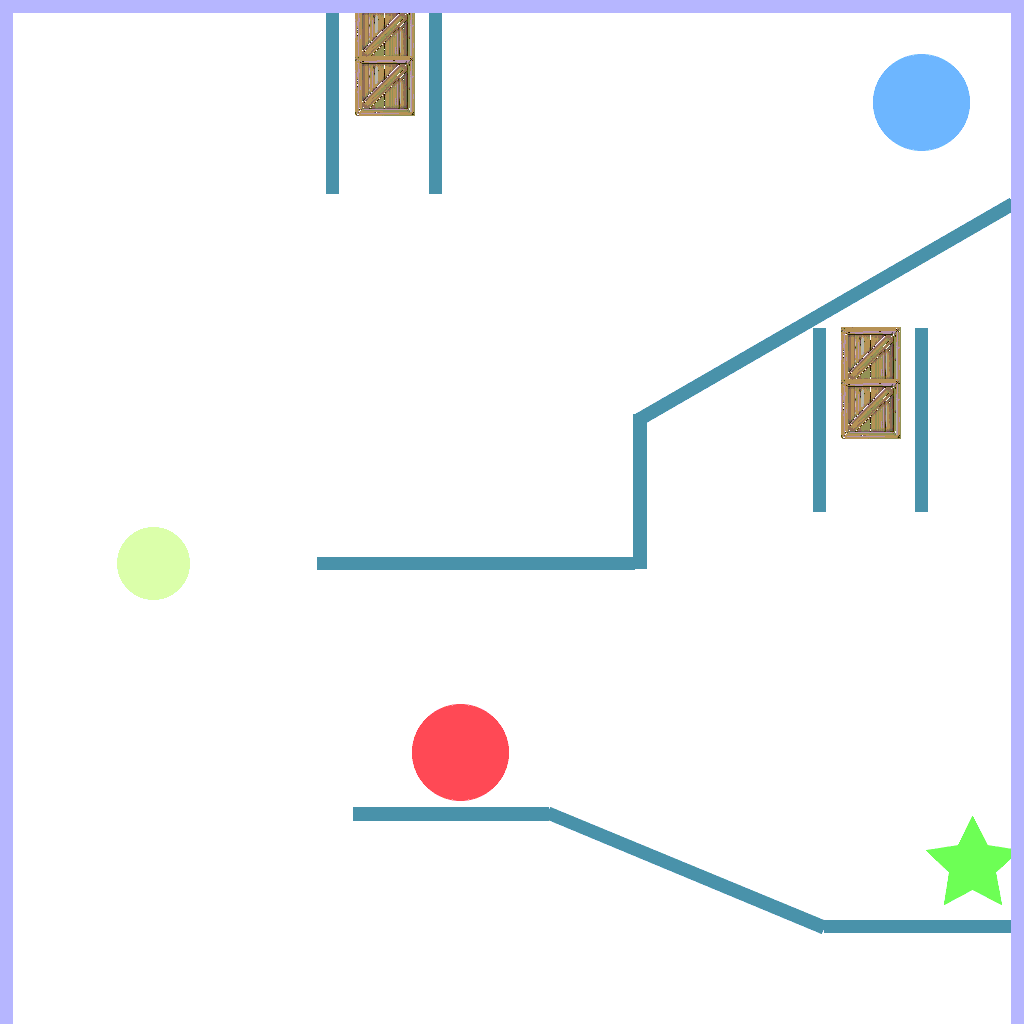
Obstacle Task
Successfully stop the falling obstacles while navigating the ball to the goal.
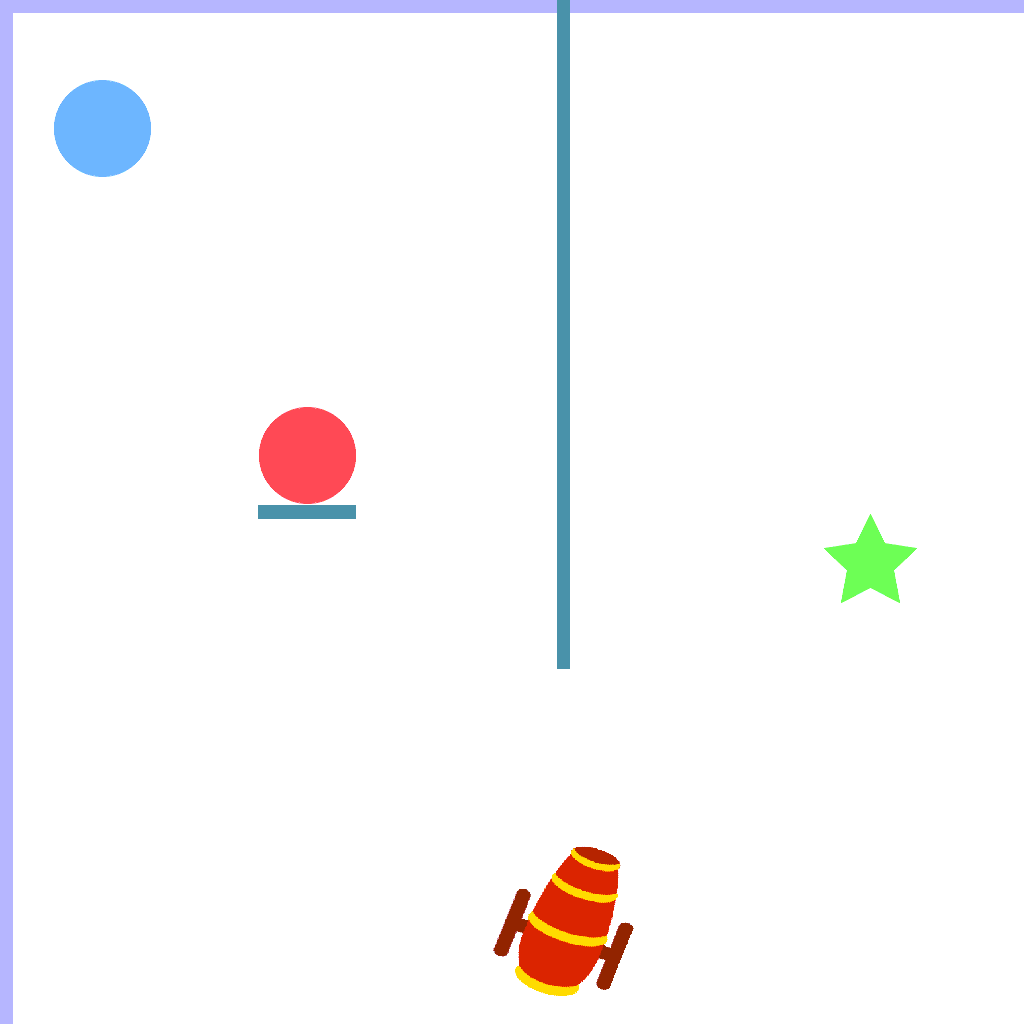
Cannon Task
Utilize the intermediate cannon to jump around the barrier.
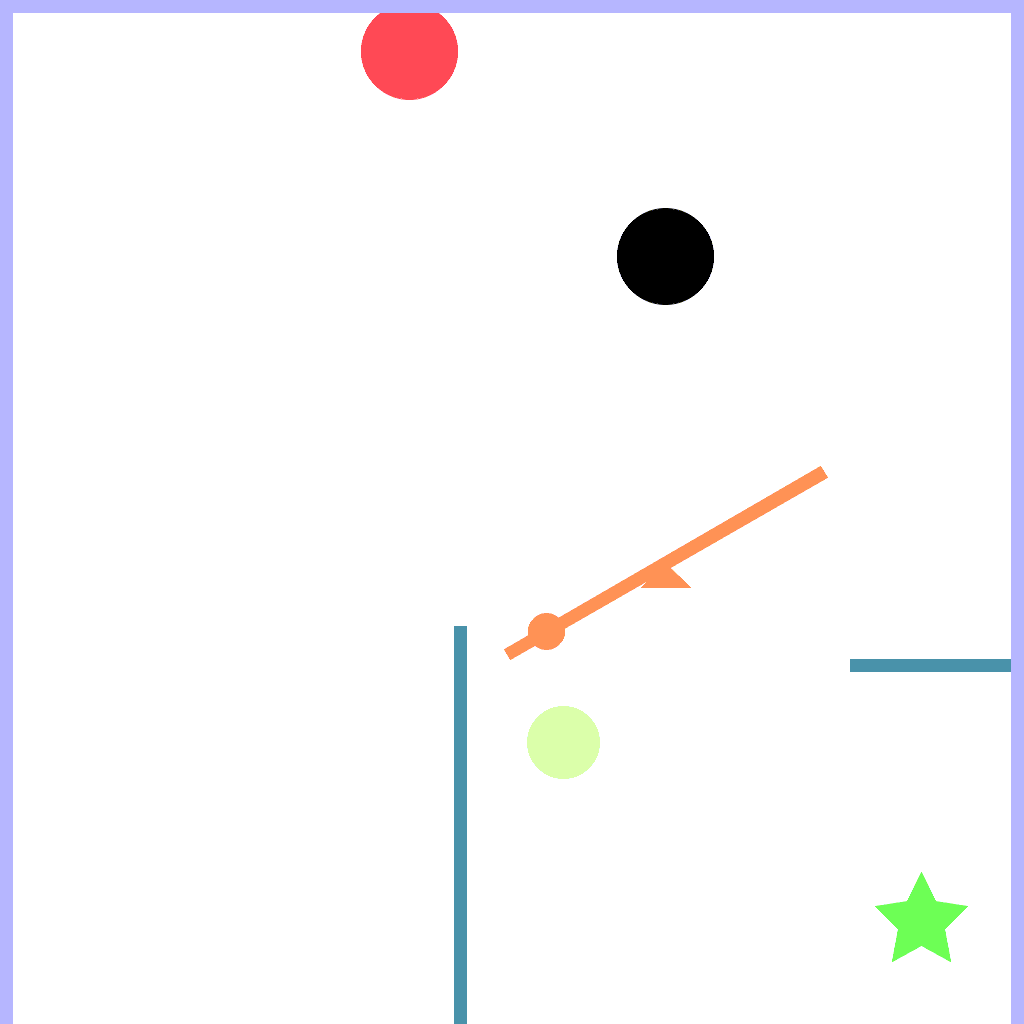
Seesaw Task
A heavy ball turns a seesaw into an obstacle to go around.
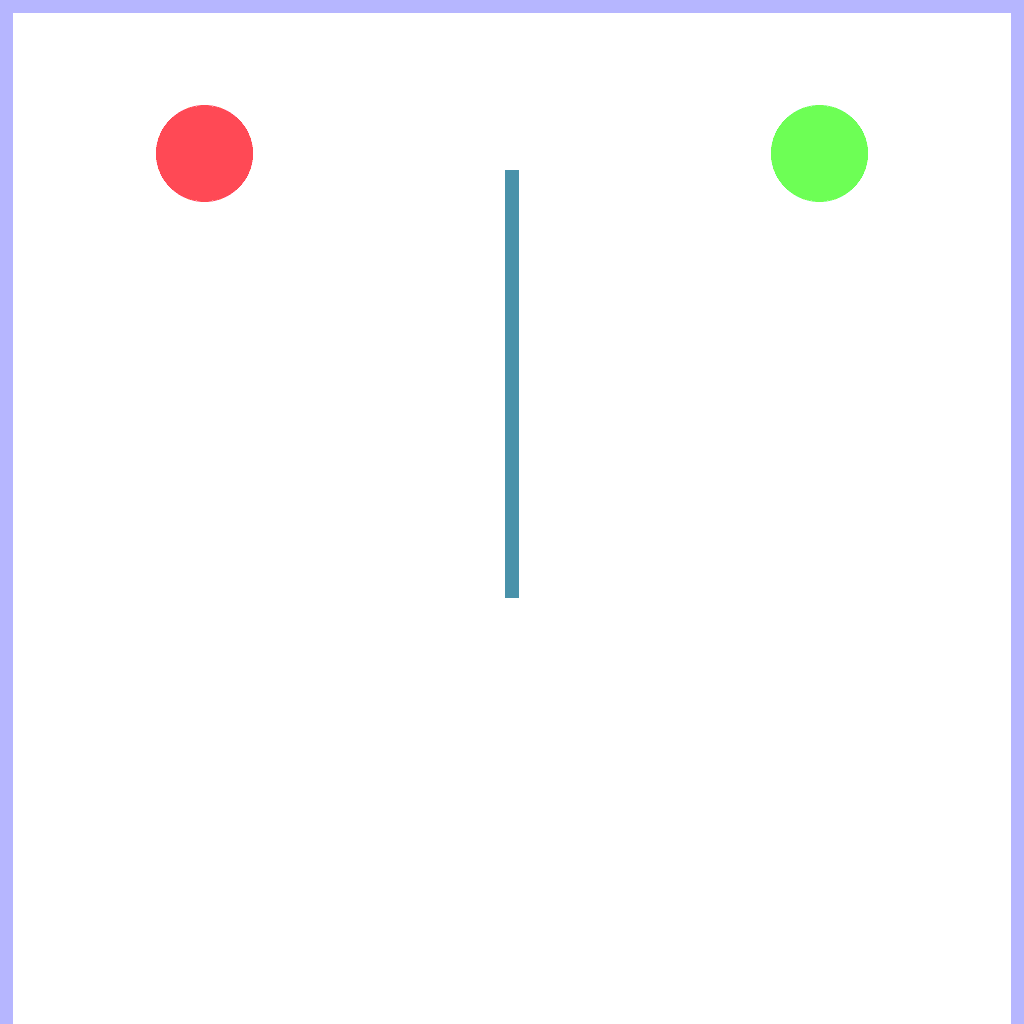
Collide Task
Your goal is moving but there is a barrier in between.

Moving Task
Make sure the timing is perfect by hitting a moving goal.
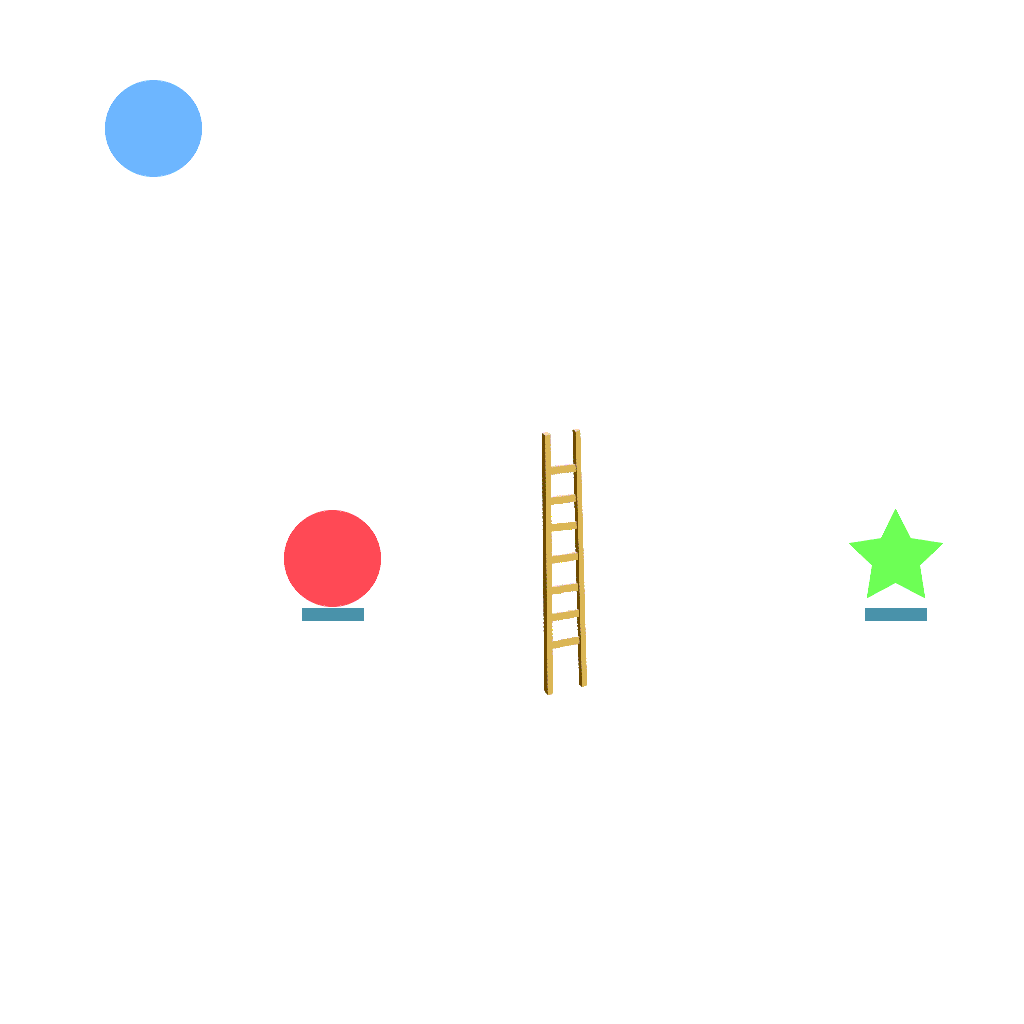
Ladder Task
Use the given ladder to get enough height to reach the goal.

Basket Task
Score a basket using the given ladders and bonus subgoals.
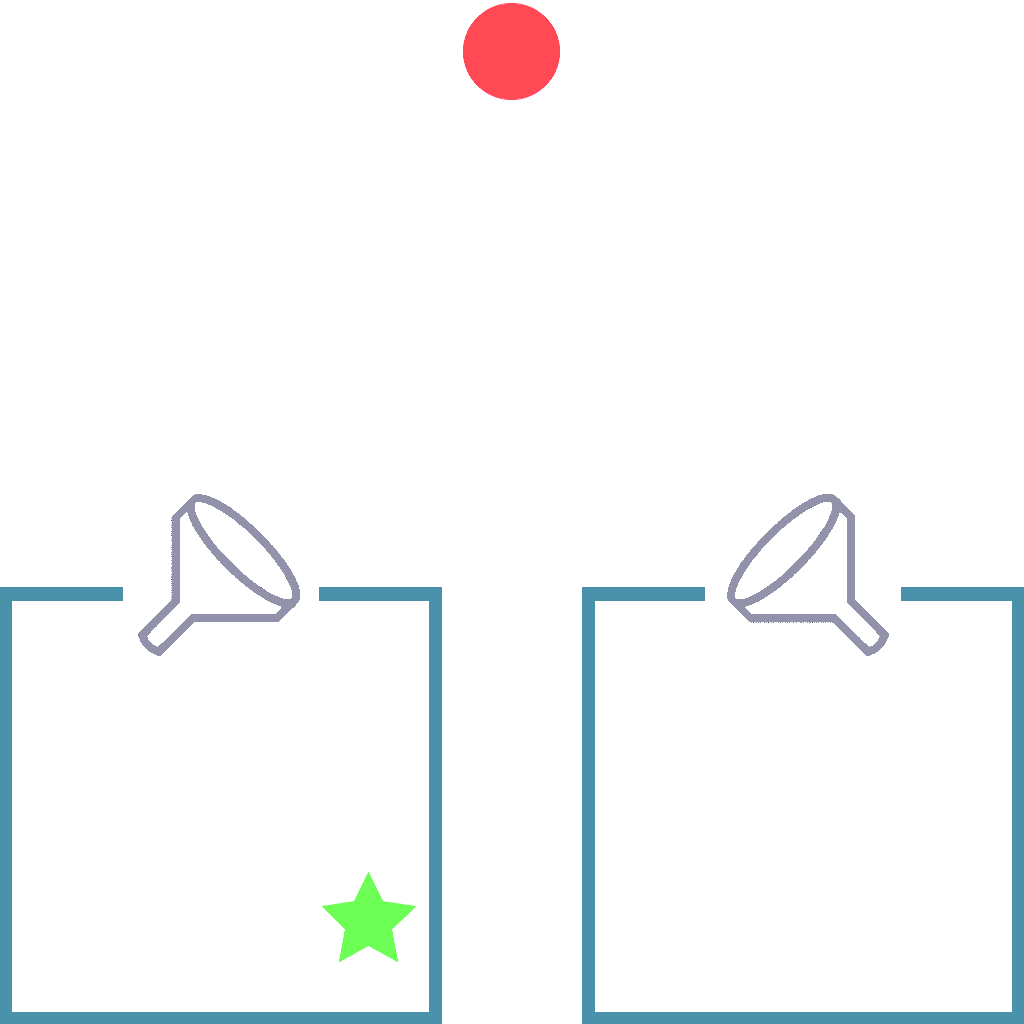
Funnel Task
Use the correct funnel to reach the goal.
Relevant Research Areas
- Reinforcement Learning for Physical Reasoning: Long-horizon Physics puzzles with diverse interactions.
- Generalization to Unseen Actions: Large and diverse action space to test generalization.
- Multi-task Learning: Diverse task distribution suitable for meta learning.
- Predictive Modeling and Model-based RL: Consistent environment and tool dynamics for learning models.
- Understanding Tool functionality and usage: Discrete (selection) + Continuous (placement) action space for tools
Installation
See the GitHub for complete instructions. First run the following in the command line to install (with at least Python 3.6):
git clone https://github.com/clvrai/create.git
cd create
pip install -r requirements.txt
Next, import the environment and use it. Again, see the GitHub for the full list of level names.
import create_game
env = gym.make('CreateLevelPush-v0')
env.reset()
done = False
while not done:
obs, reward, done, info = env.step(env.action_space.sample())
env.render('human')
Reference Paper

Contact: Andrew Szot or Ayush Jain for more details.
Citation
@InProceedings{pmlr-v119-jain20b,
title={Generalization to New Actions in Reinforcement Learning},
author={Jain, Ayush and Szot, Andrew and Lim, Joseph},
booktitle={Proceedings of the 37th International Conference on Machine Learning},
pages={4661--4672},
year={2020},
editor={III, Hal Daumé and Singh, Aarti},
volume={119},
series={Proceedings of Machine Learning Research},
month={13--18 Jul},
publisher={PMLR},
url={https://proceedings.mlr.press/v119/jain20b.html}
}